Modern businesses don’t just run on Salesforce—they run on entire ecosystems of applications. At Heroku, we operate dozens of services alongside our Salesforce instance such as billing systems, user management platforms, analytics engines, and support tools. Traditional approaches to unifying this data create more problems than they solve.
In this article, we’ll see how we unified Salesforce and multi-app data into a real-time analytics platform that processes over 10 TB data monthly with 99.99% uptime. We’ve built a data warehouse architecture that eliminates ETL complexity while delivering real-time insights across our entire technology stack. Here’s how we did it and why this approach fundamentally changes data integration.
The Data Integration Challenge: Where Traditional ETL Fails
Similar to most companies, we faced issues where we had scattered data across Salesforce and multiple application databases with no unified analysis capability.
When dealing with Salesforce Apps, traditional ETL creates cascading problems: Salesforce API bottlenecks hit, daily API limits restrict data freshness, complex SOQL queries consume precious API calls, rate limiting causes pipeline delays when you need insights most, and developers are busy managing quotas instead of analyzing data.
With our multi-app Heroku ecosystem—including billing, user management, analytics, and support—complexity multiplies these challenges. This traditional approach results in:
- Separate ETL processes for each application database
- Production database load affecting application performance
- Complex integrations that break with schema changes
- No unified customer view across systems
Infrastructure overhead compounds problems with expensive ETL tools, manual schema management, fragmented monitoring, and dedicated teams just to maintain data pipes.
The Heroku Solution for Architectural Modernization
We leveraged Heroku’s unique position within the Salesforce ecosystem. Instead of fighting API limits and complex integrations, we built an architecture that works with the Heroku platform’s strengths:
- Native Salesforce integration through Heroku Connect eliminates API limitations
- Zero-impact data access via Heroku Postgres follower databases protects production performance
- A unified analytics platform provides a single warehouse for all data
- Heroku AI PaaS allows teams to focus on insights, not infrastructure management
- For any custom requirements, you could build an app using any programming language and deploy to production with the ease of Heroku AI PaaS
The result: We process over 10 TB of data monthly from 20+ data sources while maintaining 99.99% uptime and sub-minute data freshness.
The Heroku Data Warehouse and Data 360 (Salesforce Data Cloud) Synergy
Our architecture is designed to serve two purposes: providing real-time operational analytics for Heroku applications and acting as a low-latency staging layer for the broader enterprise. This data warehouse is perfectly positioned to complement the strategic power of Data 360 (Salesforce Data Cloud). Data 360 is focused on creating the unified customer profile and powering AI-driven business actions, while the Heroku data warehouse handles the high-volume, pro-code, operational data from your applications, ensuring that all mission-critical app data is integrated and available with sub-minute freshness to feed the Customer 360 view.
Architecture: How We Built It

Five core components work together seamlessly to bring this Data Warehouse to life:
1. Central Data Warehouse: Heroku Postgres + AWS Redshift
Heroku Postgres serves as our primary data warehouse, handling real-time operational analytics and serving as the staging area for all incoming data. This enables sub-minute query responses for dashboards and operational reporting.
AWS Redshift powers our historical analytics layer, optimized for complex analytical workloads. It handles petabytes of historical data with automatic compression.
A Note on Tiered Storage and Scale: Our production environment currently uses this tiered approach to leverage Redshift’s optimized columnar storage for historical analysis. However, for architects planning a new build today, Heroku is innovating to simplify this model. The upcoming Heroku Postgres Advanced tier is built for massive scale (over 200TB storage) and 4X throughput in initial tests, offering the potential to consolidate large-scale historical storage and complex query capacity, further reducing architectural complexity.
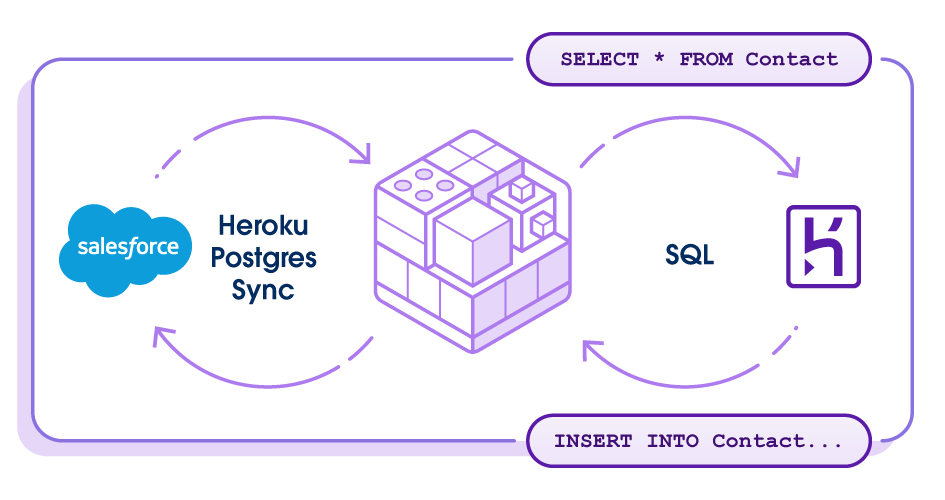
2. Salesforce Integration: Heroku Connect
Heroku Connect fundamentally changes Salesforce data integration by providing direct database replication that bypasses API constraints entirely.
- No API Limits: It uses direct replication, not API calls.
- Real-Time Sync: It provides sub-minute latency vs. hours with traditional ETL.
- Bidirectional Capability: You can write to Salesforce from the warehouse and vice-versa.
- Production Scale: It operates through 12 regional instances deployed globally for scale, compliance, and reliability.
3. Source Application Data: Heroku Postgres Follower Databases
The breakthrough came from realizing we needed better database architecture, and not complex ETL.
- Heroku Postgres Follower Databases provide read-only replicas that protect app performance while providing real-time production data access.
- A simple one-command setup eliminates complex ETL infrastructure.
- We integrate 20+ source Heroku systems (billing, addons, pipelines) following a simple pattern: create a follower, store the connection string, and use template-driven jobs. Adding new apps scales linearly.
4. Orchestration: Apache Airflow
Managing 200+ jobs across 20+ sources requires sophisticated orchestration. Apache Airflow, hosted on Heroku, orchestrates everything through 30+ DAGs, ensuring 99.99% pipeline uptime across all data sources.
- Production architecture: 30+ DAGs organized by frequency and business function—hourly DAGs for real-time metrics, daily DAGs for comprehensive reporting, weekly DAGs for trend analysis, and monthly DAGs for historical aggregation. Complex dependency management ensures data consistency across all sources while enabling parallel processing where possible. Apache Airflow’s retry capability helps avoid failures/data-loss.
- Template-driven system: We created templates in Python code for incremental load, bulk load, date range load and have 200+ JSON job definitions to standardize data flow. Templates generate dynamic SQL. Incremental loading reduces transfer 90%. Atomic operations ensure zero-downtime updates.
- Heroku Connect integration: A dedicated monitoring DAG runs every 5 minutes, checking sync status across all 12 regional Heroku Connect instances and automatically retrying failed records. This proactive approach achieves 99.99% pipeline uptime while maintaining data freshness.
5. Analytics and Reporting: Tableau Integration + Heroku Dataclips
Tableau connects directly to both Heroku Postgres for real-time operational dashboards and Redshift for historical trend analysis. Heroku Dataclips provides instant SQL-based reporting directly from Heroku Postgres, offering lightweight, shareable, ad-hoc analytics for operational teams.
- Direct connectivity: It eliminates intermediate data movement for analytics and reduces latency. Tableau connects directly to both Heroku Postgres for real-time operational dashboards and Redshift for historical trend analysis, providing users with the right data source for their specific needs.
- Enterprise capabilities: Pre-built data models and standardized metrics ensure consistency while enabling exploration and discovery. Data governance features provide audit trails and lineage tracking. Self-service analytics empowers business users to create reports and dashboards.
- Performance optimization: Tableau extracts are strategically used for frequently accessed dashboards, while live connections provide real-time data for operational use cases. This hybrid approach balances performance with data freshness requirements.
- Heroku Dataclips: provides instant SQL-based reporting directly from your Heroku Postgres data warehouse, enabling teams to create shareable reports and dashboards without additional BI tools. This complements our Tableau integration by offering lightweight, ad-hoc analytics for operational teams who need quick access to data without complex dashboard setup.
What’s New from Heroku: Accelerating Your Data Strategy
The Heroku data warehouse architecture is proof of Heroku platform’s power, which continues to evolve as the Salesforce AI PaaS. We eliminate complexity and deliver enterprise-scale results.
To keep building with confidence and explore the latest advancements, read our post on new Innovations that expand the capabilities of every Salesforce Org. Key data features include:
- Heroku Postgres Advanced Tier: Delivering massive scale (over 200TB storage), 4x throughput, and decoupled compute/storage for non-disruptive, zero-downtime scaling.
- Expanded Heroku Connect Capabilities: Supporting data synchronization for 170+ standard Salesforce objects and adopting CDC Accelerated Polling to go from an update every 10 minutes to event-based and sync changes as they happen.
- Zero-Copy Data Cloud Ingestion (Beta): Enabling customers to easily bring existing Heroku Postgres data into Data 360 (Data Cloud) with zero data movement, which provides complementary data services to optimize Data Cloud architectures.
Conclusion: Performance and Impact at Scale
This architecture has transformed how we approach data integration, proving that the right platform choices eliminate traditional ETL complexity while delivering enterprise-scale results. By leveraging Heroku’s native Salesforce integration and managed infrastructure, we’ve built a data warehouse that scales effortlessly and maintains itself. The numbers demonstrate what’s possible when you stop fighting against platform limitations and start building with them.
Performance and Impact at Scale
- Performance at Scale: We built an easy-to-maintain Data warehouse on Heroku with over 10 TB data across Salesforce and 20+ Heroku apps.
- Pipeline Reliability: We run 200+ automated jobs for data load, maintaining sub-minute data freshness for critical metrics and 99.99% pipeline uptime with automated recovery.
- Cost and Operational Benefits: With Heroku, we eliminated expensive ETL infrastructure using follower databases. reducing data integration costs by 60% compared to traditional ETL tools. Dynamic scaling optimizes costs automatically, and we reduce operational overhead through managed platforms and unified monitoring across all sources.
- Business Impact: Our solution provides real-time insights that enable data-driven decisions. The unified customer view combines Salesforce and app data, improving customer analysis accuracy by 40%, and self-service analytics eliminates engineering bottlenecks.
This architecture eliminates ETL complexity while delivering real-time insights across your Salesforce and multi-app ecosystem. Heroku’s native integrations and managed platform focus you on business value, not infrastructure management.
The approach grows with you: start with Heroku Connect for Salesforce data, add follower databases for critical apps, then expand analytics as needs evolve. Each step builds on the previous without architectural changes.
Ready to unify your Salesforce and application data for your Data Warehouse? Contact Heroku Sales for architecture consultation and implementation guidance.