What is Kafka?
Apache Kafka is a distributed commit log for fast, fault-tolerant communication between producers and consumers using message based topics. Kafka provides the messaging backbone for building a new generation of distributed applications capable of handling billions of events and millions of transactions.
Why Apache Kafka on Heroku?
Access event streams in Heroku and Amazon
Seamlessly and securely connect Apache Kafka on Heroku to resources in one or more Amazon VPCs via PrivateLink.
Bring your own key (BYOK)
Deploy a new Apache Kafka service with your own key created and managed in your private AWS KMS account. You can block access from anyone, at any time, by revoking the key, giving you full control and custody of your sensitive data.
Streaming Data Connectors
With Heroku’s effortless Change Data Capture (CDC) process, quickly configure a connector to monitor one or more Postgres tables for writes, updates, and deletes, and then write each change to an Apache Kafka on Heroku topic.
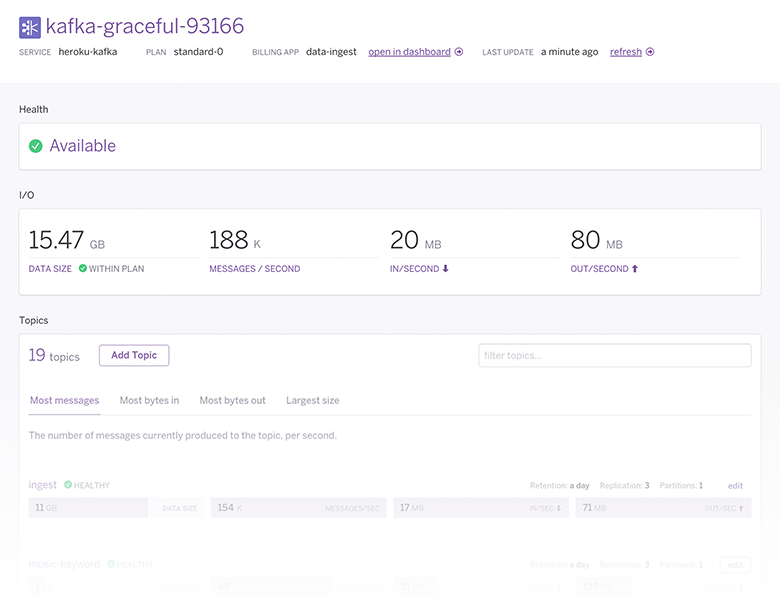
heroku addons:create heroku-kafka:standard-0 -a kafka-demo
Creating cooking-kindly-6535... done, (free)
Adding cooking-kindly-6535 to kafka-demo... done
Setting KAFKA_URL and restarting kafka-demo... done, v3
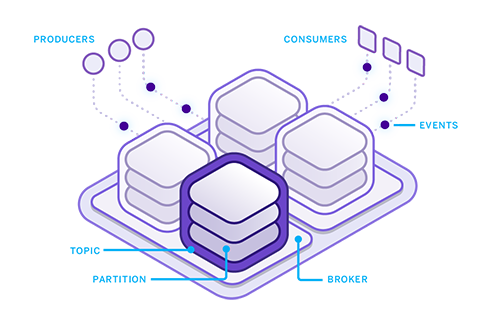
How it works
Kafka provides a powerful set of primitives for connecting your distributed application: messages, topics, partitions, producers, consumers, and log compaction.
Messages
Kafka is a message passing system, messages are events and can have keys.
Brokers
A Kafka cluster is made up of brokers that run Kafka processes.
Topics
Topics are streams of messages of a particular category.
Partitions
Partitions are append only, ordered logs of a topic’s messages. Messages have offsets denoting position in the partition. Kafka replicates partitions across the cluster for fault tolerance and message durability.
Producers
Producers are client processes that send messages to a broker on a topic and partition. Producers can use a partitioning function on keys to control message distribution.
Consumers
Consumers read messages from topics' partitions on brokers, tracking the last offset read to coordinate and recover from failures. Consumers can be deployed in groups for scalability.
Log compaction
Log compaction keeps the most recent value for every key so clients can restore state.
Build data intensive apps
Documentation

Tutorials and other resources
- Kafka Stream Processing Demo
- Introducing the Streaming Data Connectors Beta: Capture Heroku Postgres Changes in Apache Kafka on Heroku
- Heroku Postgres Streaming Data Connectors Demo
- Heroku Metrics: There and Back Again
- Powering the Heroku Platform API: A Distributed Systems Approach Using Streams and Apache Kafka
Tech session
Building Event Driven Architectures with Kafka on Heroku
Apache Kafka can be used to stream billions of events per day — but do you know where to use it in your app architecture? Find out at our technical session. See a live demo and hear answers to questions from Heroku product experts.
Podcast
Apache Kafka at Heroku, with Thomas Crayford
Listen to our podcast with Software Engineering Daily from October 25th, 2016.
Apache Kafka is a durable, distributed message broker that’s a great choice for managing large volumes of inbound events, building data pipelines, and acting as the communication bus for microservices. In this Software Engineering Daily podcast, Heroku engineer, Tom Crayford, talks about building the Apache Kafka on Heroku service, challenges we faced, and why we focused on Kafka in the first place.