Building AI applications that can interact with private data is a common goal for many organizations. The challenge often lies in connecting large language models (LLMs) with proprietary datasets. A combination of Heroku Managed Inference and Agents and LlamaIndex provides an elegant stack for this purpose.
This post explores how to use these tools to build retrieval-augmented generation (RAG) applications. We’ll cover the technical components, Use Cases and the development process, and how to get started.
LlamaIndex for data orchestration
LlamaIndex is an open-source framework for building context-aware LLM applications. Its core function is to orchestrate a retrieval-augmented generation (RAG) pipeline, which manages the entire data lifecycle for your application.
It uses data connectors from LlamaHub to ingest information from various sources (like Slack, Notion, Google Docs, or APIs), indexes that data into a searchable knowledge base, and then retrieves the most relevant context to help an LLM answer user queries accurately. In essence, it makes your private data accessible and useful for the LLM.
Heroku AI for managed inference
Heroku is an AI PaaS designed to simplify building, deploying, and scaling AI applications. Heroku AI provides several primitives useful for RAG applications
- Managed Inference for models like Anthropic’s Claude Sonnet through a OpenAI compatible API
- Embedding models like Cohere’s Embed Multilingual to convert text data into vector representations for search.
- The pgvector extension for Heroku Postgres enables vector search capabilities, allowing it to function as a vector store.
- Heroku also provides an easy way to access data using Model Context Protocol (MCP) and AppLink to securely connect to your Salesforce org
Understanding retrieval-augmented generation (RAG)
Retrieval-augmented generation (RAG) is a technique that improves LLM outputs by providing them with relevant information retrieved from an external knowledge base. Instead of relying solely on its pre-trained data, the LLM can reference this external data before generating a response.
Common use cases for RAG and agents
The value of this stack becomes clear when applied to specific business problems that involve querying large volumes of documents.
- In financial analysis, professionals can bypass the time-consuming manual search of dense reports and instead use the RAG system to receive a synthesized answer with the relevant context retrieved directly from the document.
- The insurance industry can build powerful agents. For example, an agent could be tasked with assessing a claim for hail damage. It would first use a RAG tool to retrieve the specifics of the customer’s auto policy from a knowledge base. Then, it might use a weather data API as a second tool to verify if a hailstorm was reported in the customer’s location on the specified date. Finally, the agent would synthesize these findings to determine if the policy covers the event and generate a summary for a human adjuster.
- For customer support and internal knowledge, RAG can power chatbots built on top of scattered knowledge bases like FAQs and HR policies.
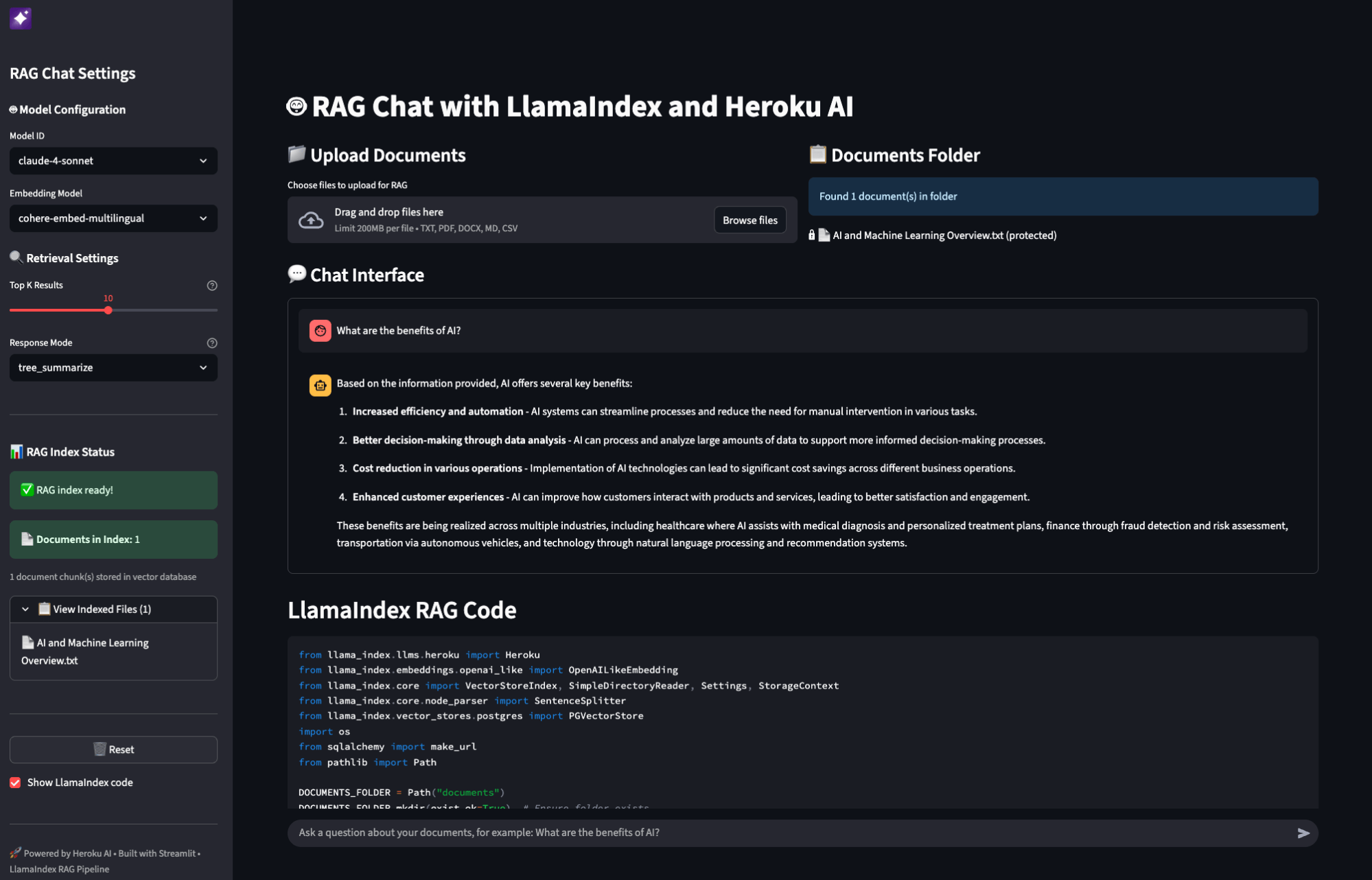
Building a RAG application with Heroku AI and LlamaIndex
The integration between LlamaIndex and Heroku Managed Inference and Agents streamlines the development of RAG applications.
First, provision the necessary Heroku resources: a Postgres database with pgvector, a Claude 4 Sonnet model for inference, and Cohere model for embeddings.
heroku addons:create heroku-postgresql:essential-0 --app your-app-name --wait
heroku pg:psql --command "CREATE EXTENSION vector" --app your-app-name
heroku addons:create heroku-managed-inference:claude-4-sonnet --as INFERENCE --app your-app-name
heroku addons:create heroku-managed-inference:cohere-embed-multilingual --as EMBEDDING --app your-app-name
Next, use LlamaIndex in your Python application to connect to these services. Since Heroku provides an OpenAI-compatible API for its embedding service, we can use LlamaIndex’s OpenAILikeEmbedding class by pointing it to the correct Heroku environment variables.
from llama_index.llms.heroku import Heroku
from llama_index.embeddings.openai_like import OpenAILikeEmbedding
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext
from llama_index.vector_stores.postgres import PGVectorStore
from sqlalchemy import make_url
import os
llm = Heroku()
# Use OpenAILikeEmbedding class pointed at Heroku's service
# It reads the EMBEDDING_URL, EMBEDDING_KEY, and EMBEDDING_MODEL_ID from env vars
embed_model = OpenAILikeEmbedding(
api_base=os.environ.get("EMBEDDING_URL") + "/v1",
api_key=os.environ.get("EMBEDDING_KEY"),
model=os.environ.get("EMBEDDING_MODEL_ID")
)
# Load data from a local directory
documents = SimpleDirectoryReader("your_data_directory").load_data()
# Connect to the Heroku Postgres database with pgvector support
# The DATABASE_URL config var is automatically set by Heroku and contains the connection string
# We need to parse the connection string and pass it to the PGVectorStore
database_url = os.environ.get("DATABASE_URL").replace(
"postgres://", "postgresql://")
url = make_url(database_url)
vector_store = PGVectorStore.from_params(
database=url.database,
host=url.host,
port=url.port,
user=url.username,
password=url.password,
table_name="my_vector_table",
embed_dim=1024 # Cohere embeddings have a dimension of 1024
)
# Create a storage context to store the index
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Create the index, which will embed and store the documents
index = VectorStoreIndex.from_documents(
documents,
vector_store=vector_store,
embed_model=embed_model,
storage_context=storage_context
)
# Create a query engine to interact with the data
query_engine = index.as_query_engine(llm=llm)
response = query_engine.query("What is the main takeaway from my documents?")
print(response)
This code snippet demonstrates how to load documents, create embeddings with Cohere, store them in pgvector, and query them with Claude Sonnet 4, all orchestrated by LlamaIndex on Heroku.
You can find a complete and deployable version of the previous code snippet in our Heroku Reference Applications repository.
Start building with Heroku AI and LlamaIndex
The combination of Heroku Managed Inference and Agents, and LlamaIndex provides a practical toolset for building data-aware AI applications. This stack allows developers to build applications that leverage private data sources with managed infrastructure. For developers building AI applications that require integration with proprietary data, the Heroku and LlamaIndex stack offers a great solution.